
Balena Architecture¶
The following architecture diagram illustrates the priciple components of Balena. Most HPC services will have a boradly similar structure:
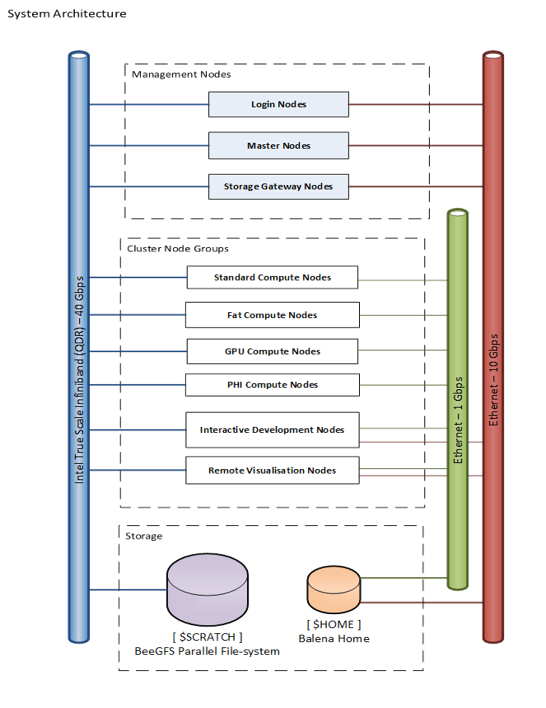
The key thing to understand is that HPC are a collection of resources similar to what you have in your desktop or laptop machine, typically called nodes. The are different sets of nodes each performing a different purpose. When you access Balena you don't go straight to the compute nodes you land on a login node. Here you can submit jobs to a scheduler, which assigns jobs to the compute nodes. The scheduler runs on master nodes which are also used to manage the system, maintenance and fix any issues.
The compute are connected by a high speed network which allows several or many nodes to work together on the same problem. Most of the nodes are the similar but to target specific workloads we also have some with high memory and some with GPU accelerators. As there can often be a queue of user jobs waiting to run we also have nodes reserved for quick turn around and interactive testing to allow researchers developing software to work more efficiently. Because the nodes all need to access the same storage this is separate, and as we have already seen, in the case of Balena has two component, $HOME and $STORAGE.
Some HPC problems require access to large datasets and reading and writing that data can be a significant bottleneck. Therefore the $STORAGE is also connected to the high speed network. Making backups of this storage would be prohibitively expensive, reducing the capacity. So this data is considered at risk and we have $HOME where users can store programs and scripts for setting up and running calculations, this has a smaller capcity but is backed up. This is connected to a standard network which also allows the system to be managed without intefering with jobs that are running.